

提升Ruby on Rails性能的几个解决方案


简介
Ruby On Rails 框架自它提出之日起就受到广泛关注,在“不要重复自己”,“约定优于配置”等思想的指导下,Rails 带给 Web 开发者的是极高的开发效率。 ActiveRecord 的灵活让你再也不用配置繁琐的 Hibernate 即可实现非常易用的持久化,Github 和 Rubygems 上丰富多样的 Rails 插件是 Rails 开发高效率的又一有力保障。Rails 是一个真正彻底的 MVC(Model-View-Controller) 框架,Rails 清楚地将你的模型的代码与你的控制器的应用逻辑从 View 代码中分离出来。Rails 开发人员很少或者可能从未遇到过某些代码该放于哪一层的困扰,在 Rails 的世界中,你的代码的职责很清楚的被定位,你可以轻松的决定出它们应该位于哪一层。Rails1.2 之后的版本开始支持 Rest Service,通过这些内嵌的特别,你在开发你 Web 应用,展现给用户 HTML 的页面的同时,几乎不费吹灰之力,就可又提供基于 Rest API 的 Web Service,另外,你也可以方便的像使用基本数据的 Model 一样的去消费第三方提供的基于 Rest API 的 Web Service。
通过搜索引擎,你可以找到很多类似于用 Ruby On Rails 十五分钟创建 Blog 系统等类似的使用 Rails 进行快速开发的文章。 Ruby On Rails 对于敏捷开发过程的也是非常友好,在 Rails 框架中集成了 Unit Test, Function Test 对你的 Model 和应用逻辑进行测试。通过这些,你不需要再安装任何插件或者程序库便可方便的进行测试驱动开发,通过 Watir 的支持,你可以轻松的用 Ruby 代码实现基于浏览器的自动测试。 另外,在 Rspec 等插件的支持下,你甚至可以进行行为驱动开发(Behaviour Driven Development),让你的测试代码变得更加有意义,也更加容易被客户所接受。
虽然 Rails 的优点你可以一下子列出很多,你也可能会拿出用 Java/Hibernate/Spring/Struts 和 Ruby On Rails 开发同样功能 Web 应用程序的代码行比较来举例,或者提供进行 Java/Hibernate/Spring/Struts 和 Ruby On Rails 开发所需要接受的培训资料的书籍的对比照片来举例,但我们都不可避免的会面对可伸缩性(Scalability)的问题。很多 Web 应用会面对大量的用户群,这样的应用会遇到很大的并发带来的性能的考验。 Rails 在这一点上,并没有让所有人信服,依然有很多的系统架构师和工程师对 Rails 是否适用于开发高负载高并发的 Web 应用持怀疑的态度。但不可否认,随着 twitter, friends for sale,basecamp 这类大负载量的应用的出现,Rails 也越来越被认识是可扩展的,这些成熟的应用也告诉我们,开发出同时处理数百万用户请求的 Rails 应用是可能的。Ruby On Rails 框架在可伸缩性上为人诟病无非集中于以下几点,Ruby 语言本身性能问题,Ruby On Rails 缺少成熟的高性能的应用服务器,对数据库扩展的支持,互联网上缺乏可熟可靠的网络提供商等等。 本文将从这些点出发,介绍具可伸缩性的 Rails 应用程序的部署架构,以及开发高性能的 Rails 应用程序的一些比较好的具体实践。
通常的 Web2.0 应用,特别是高负载的应用,除了 Web 和应用服务器选择 , 负载均衡这类部署需要面对的问题之外,通常还必须得面对后台任务,高性能全文搜索这些开发上的问题,这些在 Java 或者 PHP 这些比较成熟的开发环境里面都有比较成熟的方案,开发和架构人员通常都会有多种选择,结合具体应用做出架构设计。在新兴的 Rails 社区,这些还并不完善和成熟,本文将介绍一些高性能可伸缩的 Rails 应用程序的开发和部署的具体实践,针对通常 Web 2.0 网站所遇到的具体问题做出分析和解决方案,旨在给 Rails 开发者提供具体的参考。本文将介绍的内容可以用下图来综合表示:
图 1. 本文总体结构
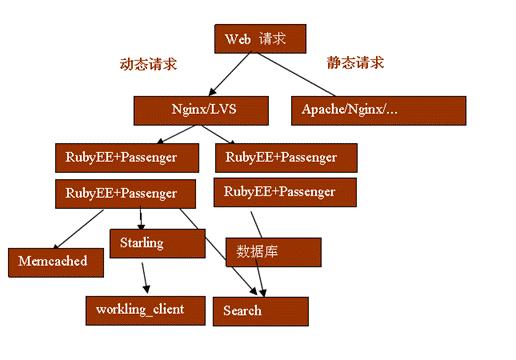
使用 Nginx+Passenger 来替代 Apache+Mongrel 来部署 Rails 应用
事实上,进行 Rails 部署可以描述得非常简单,我们需要一些机器配置我们的环境,为了性能和成本,我们理所当然选用 Linux 系列的服务器,可选的有 CentOS,Debian, Ubuntu Server 等。本文的所有程序,命令以及代码如非特别说明,都默认是以 Linux 为基本环境的。 然后我们需要数据库存储我们的数据,我们可以选用免费的 Mysql,然后我们便开始开发我们的 Web 应用的 Rails 代码,部署时,我们需要支持 Ruby On Rails 的应用服务器让我们的 Rails 代码跑起来,这可能是 Rails 自带的 Webrick,当然这个可能性极小,也可能是 FastCGI, 或者是 Mongrel,Thin, Passenger 等等,然后我们通过 Apache,Nginx,Lighttpd,HAProxy 之类的 Web 服务器访问我们的应用服务器,这个访问可以直接通过 HTTP 协议,也可以是 FastCGI,或者是自定义的其它协议,如此这般,我们便可以通过浏览器访问我们的应用程序了。如下图所示,这便是通常的 Rails 应用程序部署结构。
图 2. Rails 应用程序部署结构

对于前端的 Web Server,Apache 是事实上的工业标准,在 Web 服务器市场,是占有率最高的,全球大量的网站采用 Apache 来部署他们的应用,Apache 是一款成熟稳定的 Web 服务器,功能非常强大,提供对几乎所有 Web 开发语言和框架的扩展支持,在对 Rails 框架的支持上,我们可以采用 mod_fcgid 模块,通过 FastCGI 协议与 Rails 进程通讯。或者利用 mod_proxy_balancer 对后端的独立的 Rails 服务器如 Thin Cluster,Mongrel Cluster 或者 Apach/Nginx+Passenger 进行 HTTP 分发。但 Apache 作为一个通用的服务器,在性能上和一些轻量型的 Web 服务器相差甚远。Apache 的 mod_proxy_balancer 模块的分发性能不高,比 Nginx 或者 HAproxy 都相差很多,另外,Apache 目前并不支持 Event(事件)模型,它仅支持 Prefork(进程)模式和 Worker(线程)模式,每处理一个链接,就需要创建一个进程或线程,而一些轻量级 Web 服务器如 Nginx 和 Lighttpd,则都很好地利用内核的事件机制提高性能,极大减少线程或进程数量,降低系统负载。
Nginx 是一个轻量级的高效快速的 Web 服务器,它作为 HTTP 服务器和反向代理服务器时都具有很高的性能。Nginx 可以在大多数 Unix like OS 上编译运行,并有 Windows 移植版。 Nginx 选择了 Epoll 和 Kqueue 作为开发模型,它能够支持高达 50,000 个并发连接数的响应,可以在内部直接支持 Rails 和 PHP 程序对外进行服务。另外,Nginx 作为负载均衡服务器,也可以支持作为 HTTP 代理服务器对外进行服务 , Nginx 不论是系统资源开销还是 CPU 使用效率都比 Apache 要好很多。当你打开 Nginx 官方网站,你会发现一个如此知名的 Web 服务器产品的官方主页竟然如此简单,其实,Nginx 本身就是一个安装非常简单,配置文件非常简洁,甚至可以在配置文件中使用 Perl 语法。
在处理静态文件上, Apache 和 Nginx 都可以胜任。但对于应用服务器或者是前端的负载均衡服务器,我们推荐 Nginx 而不是相对 Nginx 较为重量级的 Apache。
对于应用服务器,Mongrel 一度是最流行的部署方式,它的 HTTP 协议的解析部分是用 C 语言编写的,效率上有所保证。Mongrel 使用了 Ruby 的用户线程机制来实现多线程并发 , 但是 Ruby 并不是本地线程 ,Rails 也不是线程安全的,因此 Mongrel 在执行 Rails 代码的过程中,完全是加锁的状态,那和单进程其实也没有太大差别。所有我们在使用 Mongrel 来部署 Rails 应用程序时,一般是在后台启动一个 mongrel_cluster 来启动多个 Mongrel 进程,如我们在 mongrel_cluster.yml 中进行如下配置可以在 8000~8009 端口启动 10 个 Mongrel 进程。
清单 1. Mongrel_cluster.yml 配置
--- cwd: /var/www/test_app log_file: log/Mongrel.log port: "8000" environment: production debug: false pid_file: log/mongrel.pid servers: 10
这样的部署方式实际上也限制了 Mongrel 处理大并发应用的能力,在处理大数据量请求的时候,Mongrel 进程经常被挂过,但并发数一多,就会出现所有的 Mongrel 进都会被挂过的情况,这样前端的服务器便得不到返回,整个 Web 应用就陷入瘫痪。所以,Mongrel 并没有被广泛采用,很多网站宁愿坚持使用最古老的 FastCGI 的部署方式也不使用 Mongrel 来部署应用,而且 Mongrel 也停止更新很久,Mongrel 的开发者已完全不再进行 Mongrel 的开发了。所以,Mongrel 并不是现在最推荐的 Rails 应用服务器。
Passenger 是类似于 mod_php 的 Rails 运行环境,而不是 Mongrel 那样是独立的 Http 服务器。Passenger 对目前主流的 apache 和 Nginx 两大 Web 服务器都有支持。Passenger 使用起来极其方便,而且它具有较高的性能,从 Passenger 官方网站公布的测试结果来看,Passenger 的性能要优于 Mongrel 服务器,目前来说,Passenger 无疑是最好的选择。Passenger 继承了 Rails"不重复自己"的惯例,通过 Passenger 部署应用程序,你仅仅需要将 Rails 项目程序文件上传到目标服务器,甚至都不需要重启服务器,非常简单。
要在 Nginx 环境下安装运行 Passenger, 你仅仅需要如下操作:
清单 2. 安装 Passenger
gem install passenger Passenger-install-nginx-module
下面的代码展示了在 Nginx 上配置 Passenger:
清单 3. 在 Nginx 上配置 Passenger
http {
...
server {
listen 80;
server_name www.test.com;
root /var/www/test/public;
passenger_enabled on;
}
...
}
通过 Nginx+Passenger 构建 Ruby On Rails 的应用服务器可以得到显著的性能提升,同时,还可以采用 Ruby Enterprise Edition 来提升 Ruby 本身的性能。这个版本也是由 Phusion 开发的,采用 copy-on-write 的垃圾回收策略,并使用 tcmalloc 来改善内存分配,他们的网站公布的数据,使用 Ruby Enterprise Edition 能比普通的 Ruby 版本减少 33% 的内存消耗。
Nginx+Passenger 就部署在一台机器上的应用服务器,但并发过大时,一台机器并不足以来提供这样的处理能力,这个时候,一般会做负载均衡,这和通常的负载均衡策略并无二异,Nginx 在使用反向代理来实现负载均衡的能力上要强于 Apache 的反向代理模块,我们可以在多台 Nginx+Passenger 的前端可以再增加一台 Nginx 的 Web 服务器。甚至为了更强的处理能力,我们也可以采用 LVS 来进行负载均衡。
使用 Starling 和 Workling 去异步执行 Rails 后台任务
在进行 Web 应用开发时,每个 Web 请求都需要迅速的得到返回,这时候有些计算量比较大的操作可以放在后台去异步执行,比如大量的数据更新操作,只需要在 Web 应用中进行触发,然后在后台进行执行。而有些操作则需要定期去执行,比如数据的备份,一些数据的统计分析,图片的处理,邮件的发送等等。这些操作如果放在 Web 应用中即时返回显然是不合适的,而且也会带来机器的负载很严重,对于 Rails 应用程序来说,除了影响用户体验,这样的操作还会阻塞 Rails 服务器实例,从而带来整体性能的下降。对于这类操作,我们可以使用一个任务队列,将需要执行的操作依次入队,然后在后台再启动进程进队列中取出这些任务,并执行,队列可以使用数据库,Memcached, ActiveMQ 或者 Amazon SQS 来实现,而后端进程则可以使用 Rails 里面的 cronjob+script/runner 或者 BackgrounDRb 等等来操作。这里要介绍的解决方案则是采用 twitter 开发人员贡献出来的采用 Memcache 协议的 Starling 消息队列和 Workling 插件来进行实现。
Starling 是 twitter 开发团队从 twitter 项目抽象出来开源的 Rails 插件,虽然说 Starling 并不完全就是 twitter 的线上版本所用的插件,但我们也可以足以相信 Starling 的性能和应对高并发的处理能力。类似的插件还有 backgroundrb,background job, background_fu。backgroundrb 是使用 drb 实现队列的消息传递,但它还有一个问题,更新队列的时候,backgroundrb 使用的是悲观锁,在大访问量的情况下,这种情况是不容允许的。 background job 和 background_fu 则是基于数据库的消息队列,在大负载量的情况下数据库的性能也不容易得到保证。而 Starling 是基于 Memcached 协议的消息队列,效率更高,也更容易伸缩,通常你可以在每台应用服务器上都运行一个 Starling 服务器,并在同一台机器或者其它机器上去运行后台程序与之交互。
我们通过如下命令来安装 Starling:
清单 4. 安装 Starling
gem sources -a http://gems.github.com/ sudo gem install starling-starling mkdir /var/spool/starling
在读取 Starling Server 时,我们需要 memcache-client,这个 gem 的 1.5.0 版本有一些问题,在 fiveruns-memcache-client 得到修正,这个 fiveruns-memcache-client gem 在 starling-starling gem 中是作为依赖项自动安装的。
安装完 Starling 之后,使用 sudo Starling -d -p 15151 这个命令来启动它,启动时用 -p 参数来指定所要使用的端口,一般加 -d 参数使它以 daemon 方式在后台运行:
为了明白 Starling 的机制和 Starling 究竟做了哪些工作,在启动了 Starling 之后,我们可以使用我们打开 irb 下面的程序来进行简单的测试:
进行简单的测试
清单 5. 测试 Starling
>> require 'starling'
=> true
>> Starling = Starling.new('127.0.0.1:15151)
=> MemCache: 1 servers, ns: nil, ro: false
>> Starling.set('test_queue', 123)
=> nil
>> loop { puts Starling.get('test_queue'); sleep 1 }
123
nil
nil
...
这里我们可以看到确实启动了 Server,然后我们向这里插入数据,我们用一个循环去访问这个队列,最后的输出便是我们想要的结果。
接下来我们安装 workling:
清单 6. 安装 workling
script/plugin install git://github.com/purzelrakete/workling.git
Workling 支持多种方式来进行后台任务操作,其中就包括上面已经安装的 Starling,安装好 Starling 后,我们需要在 Rails 应用程序中的 environment.rb 加上以下代码来配置 Workling 使用 Starling:
清单 7. 使用 workling
Workling::Remote.dispatcher = Workling::Remote::Runners::StarlingRunner.new
Workling 的配置文件在 workling.yml, 和其它 Rails 的配置文件类似,workling.yml 也可以针对不同产品模式进行不同的模式,这里仅列出 production 的配置。
清单 8. Workling 配置
production:
listens_on:localhost:15151, localhost:15152, localhost:15153
sleep_time: 2
reset_time: 30
memcache_options:
namespace: myapp
listens_on 参数即为 workling_client 去访问的 Starling 启动的地址和端口,这里可以允许多个 Starling 地址,这就意味着你启动多个 Starling 服务器,而用一个 workling_client 去调用。sleep_time 即为 workling_client 去队列中取数据的等待时间,reset_time 则定义了如果出现 memcache 错误时,workling_client 等待去重建和服务器连接的时间。 在 memcache_options 的 namespace 参数则定义了所使用的命名空间,这在同一台服务器如果为不同的 Rails 应用启动同一个 Starling 服务器时是非常有用的。
用 script/workling_client start 脚本便可以启动 workling_client 进程,有时候我们觉得一个 workling_client 不够用,我们可以修改 script/workling_client start 来支持多个 workling_client 实例,这样每运行 script/workling_client start 一次都会新启动一个 workling_client 实例。
清单 9. 多 client 的 Workling 配置
options = {
:app_name => "workling",
:ARGV => ARGV,
:dir_mode => :normal,
:dir => File.join(File.dirname(__FILE__), '..', 'log'),
:log_output => true,
:multiple => true,
:backtrace => true,
:monitor => true
}
使用 Memcached 和 cache-money 来缓存数据
Rails 自身提供四种缓存方式,即 Page Cache, Action Cache,Fragment Cache 和 ActiveRecord Cache 这三种缓存。Page Cache 是最高效的缓存机制,他把整个页面以静态页面 HTML 的形式进行缓存,这对于不会经常发生变化的页面是非常有效的。Action Cache 是对某个 action 进行缓存,与 Page Cache 的区别在于:HTTP 请求会经过 Rails 应用服务器,直到所有的 before filters 都被处理,这种缓存就能处理 Page Cache 无法处理的如需要登录验证的页面,可以所验证的步骤加入 before filter 中,Fragment Cache 则为了缓存页面中的某一部分,同一个页面中的不同部分还可以采用不同的过期策略。对于 Rails 本身的缓存机制,我们可以写 sweeper 进行过期和清除的处理。ActiveRecord Cache 则是较新版本 Rails 中新推出的对 ActiveRecord 的缓存机制,使用 SQL 查询缓存,对于同一 action 里面同一 SQL 语句的数据库操作会使用缓存。
Rails 的缓存机制能非常有效的提升网站性能,Rails 默认是将缓存存在于文件系统中,这并不是适合生产环境下的存储方式,文件 IO 的效率有限,Rails 还支持在同一进程的内存中保存 Cache,但如果有多个 Rails application,它们之间不能共享缓存。我们这里推荐的是以 MemCached 的方式进行存储,这也是目前是流行的缓存存储方式。
Memcached 是由 Danga Interactive 开发,用于提升 LiveJournal.com 访问速度的。LiveJournal.com 每秒有几千次动态页面访问量,用户 700 万。Memcached 是一个具有极高性能的分布式内存对象缓存系统 , 基于一个存储键 / 值对的哈希表。其守护进程(daemon)是用 C 写的 , Memcached 将数据库负载大幅度降低,更好的分配资源,更快速访问。可以用各种其它语言去实现客户端。上文的介绍中已经安装了 Rails 的 Memcached 客户端,因为我们只需要在 Rails 应用程序中做如下配置:
清单 10. Memcached 配置
config.cache_store = :mem_cache_store, 'localhost:11211'
便可以进行使用 MemCached 进行缓存数据。除了 Rails 本身的缓存机制,我们还直接用 Rails.cache 操作 Memcached 进行数据缓存,如,我们读取所有 blog 的数量,可以如下使用缓存:
清单 11. 使用 Rails.cache
blogs_count = Rails.cache.fetch("blogs_count") do
Blog.count
end
Rails 自身的 ActiveRecord 作用有限,只适用同一个 action 中的 SQL 查询语句进行缓存,我们需要一个更强大的 ActiveRecord 缓存,而 cache-money 更是为了解决如此问题而推出的。当 twitter 网站变得越来越稳定,逐渐摆脱被人拿来作为"Rails 无法扩展的"典型例子的阴影时,人们便期待 twitter 开发团队能向 Rails 社区有更多的贡献,cache-money 便是在 Starling 之后 twitter 团队贡献出来的另一个插件。cache-money 和 Hibernate 的二级缓存类似,是一个读写式(write-through)缓存。在 ActiveRecord 对象更新的时候不是将缓存中的数据清除,而是直接将更新的内容写入到缓存中去。
cache-money 有许多很棒的特性,如:缓存自动清除机制 ( 利用 after_save/after_destroy) ;支持事务,由于 Rails 的 Active Record 没有提供 after_commit 机制,目前常见的缓存插件在高并发下会出现缓存更新竞争冲突,而这个特性对于解决这个问题会很有帮助,可以通过 gem 来安装 cache-money:
清单 12. 安装 cache-money
gem sources -a http://gems.github.com sudo gem install nkallen-cache-money require 'cache_money'
清单 13. 配置 config/memcached.yml
production: ttl: 604800 namespace: ... sessions: false debug: false servers: localhost:11211 development: ....
清单 14. 使用 config/initializers/cache_money.rb 来初始化
config = YAML.load(IO.read(File.join(Rails_ROOT, "config", "Memcached.yml")))[Rails_ENV] $memcache = MemCache.new(config) $memcache.servers = config['servers'] $local = Cash::Local.new($memcache) $lock = Cash::Lock.new($memcache) $cache = Cash::Transactional.new($local, $lock) class ActiveRecord::Base is_cached :repository => $cache end
使用 cache-money 非常方便,不需要额外的操作,只需要在你的 Model 里面进行简单的配置,如:
清单 15. 配置 Model 来使用 cache_money
class User < ActiveRecord::Base index :name end class Post < ActiveRecord::Base index [:title, :author] end class Article < ActiveRecord::Base version 7 index ... end
然后便可以跟以前一样使用 Rails ActiveRecord 各种方法以及事务操作。如果你改变了数据库的表结构,你可以改变 Model 的版本号来使以前的缓存失效,而不需要重启 Memcached 服务器。
使用 Sphinx+LibMMSeg+Ultrasphinx 进行全文搜索
很多应用会有全文搜索的需求,当然你可以直接集成 google 或者其它搜索引擎提供的搜索服务,但如果你要更好的控制你的搜索结果,或者对你的搜索结果进行再次利用,你恐怕必须得自己实现全文搜索了。在进行中文全文搜索时,一般要考虑两个方面的问题,即所使用搜索工具的性能问题,以及中文分词的准备度。在 Java 的世界里,Lucene 是做全文搜索绝对的权威和首选,虽然它本身没有对中文分词很好的支持,但有很多第三方插件可以利用来提高中文分词的准备率和性能。Ferret 一度是最流行的 Rails 全文搜索插件,但本文推荐是效率更高的 Sphinx。Sphinx 是俄罗斯人 Andrew Aksyonoff 开发的,这个词的意思“狮身人面”,它能在一两分钟的时间内完成数百万条记录的索引,并在毫秒级的时间类返回搜索结果。 Sphinx 和数据库集成良好,可以通过配置文件,直接用来对数据库的数据进行索引,另外,Sphinx 开发了一个 SphinxSE 数据库引擎,可以在编译 Mysql 的时候直接编译到 Mysql 里面去来实现数据库级别的高效能索引。在 Rails 中使用 Sphinx 可以通过 Ultrasphinx 插件,Rails 开发人员可以使用它来很方便地调用 Sphinx 的功能。
可以从这里 http://www.sphinxsearch.com/downloads.html 下载 Sphinx
在安装好 Sphinx 后可以直接从 Rubyforge 上安装 Ultrasphinx:
清单 16. 安装 ultrasphinx
Ruby script/plugin install svn://Rubyforge.org/var/svn/fauna/ultrasphinx/trunk
LibMMSeg 就是一个中文分词程序,当前最新版本是 0.7.3,采用 C++ 开发,分词算法采用的是“复杂最大匹配 (Complex maximum matching)”,同时支持 Linux 平台和 Windows 平台,切分速度大约在 300K/s(PM-1.2G),LibMMSeg 从 0.7.2 版本开始,作者提供了 Ruby 调用的接口,所以我们可以直接在 Ruby 中用 LibMMSeg 进行分词,相当方便。LibMMSeg 可以通过 http://www.coreseek.cn/opensource/mmseg/ 来下载安装。
用户可以通过修改词典文件增加自己的自定义词,以提高分词法在某一具体领域的切分精度,系统默认的词典文件在 data/unigram.txt中。 然后通过 mmseg -u unigram.txt这个命令来产生一个名为 unigram.txt.uni的文件,将该文件改名为 uni.lib,完成词典的构造。需要注意的是,unigram.txt必须为 UTF-8 编码。
LibMMSeg 的开发者为了更好的让 Sphinx 使用 LibMMSeg 进行中文分词,为 Sphinx 开发了相关的补丁,从这里 http://www.coreseek.cn/opensource/Sphinx/ 下载两个补丁文件:
http://www.coreseek.com/uploads/sources/sphinx-0.98rc2.zhcn-support.patch
http://www.coreseek.com/uploads/sources/fix-crash-in-excerpts.patch
然后打上补丁:
清单 17. 安装 Sphinx 补丁
cd sphinx-0.9.8-rc2 patch -p1 < ../sphinx-0.98rc2.zhcn-support.patch patch -p1 < ../fix-crash-in-excerpts.patch
安装完这几个插件和补丁之后,我们便可以进行配置来让 Rails 应用程序来支持全文搜索了,
首先我们将 ultrasphinx 插件目录下的 vendor/plugins/ultrasphinx/examples/default.base复制到:config/ultrasphinx/default.base,打开这个文件,将其中的:
charset_type = utf-8改为:charset_type = zh_cn.utf-8来支持中文字符的全文检索, 并且在 charset_type 设置的下面加入一行:
charset_dictpath = /home/test/Search/lib,这个就是上文讲到的 uni.lib 字典所在的路径,然后删除所有 charset_table 相关的设置。
在 Rails 应用程序中的 Model 代码,加入全文检索支持:
如有一个 Model 为 Article,其中有两个属性叫做 title,body,我希望对这两个属性做全文检索,便可以在 article.rb 中加入一行:
清单 18. 使用 ultrasphinx
is_indexed :fields => ['created_at','title', 'body']
进行完这个配置后,我们可以使用 rake ultrasphinx:configure 这个命令来生成Sphinx 的配置文件,这条命令在 config/ultrasphinx 下创建了一个 development.conf,这个文件就是 Sphinx 的配置文件。并用rake ultrasphinx:index 这个命令来创建索引。rake ultrasphinx:daemon:start 和 rake ultrasphinx:daemon:stop 则对应着Sphinx 的searchd服务的启动和停止。searchd 会在 3313 端口启动一个 searchd,搜索请求将会全部发送到这个端口来执行。我们在控制台中进行简单的测试:
清单 19. 测试全文索引
search = Ultrasphinx::Search.new(:class_names => 'Article') search.run Search.results
一切运行正常后,我们便可以在 action 的代码中进行全文搜索了。
使用 Capistrano 进行快速部署
在进行 Rails 部署的时候你可以直接从 svn 或者 git 下面更新代码,运行 db:migrate 来进行数据库的更新,然后进行这样那样的操作后,再启动服务器,便可进行部署,即便你只有一台机器,你也会觉得太麻烦,如果你需要多台机器来运行,那你可能就会觉得每次手工部署都是一场恶梦,你可以使用 shell 脚本来简化部署的程序。在用 Rails 开发应用时,你可以使用 Capistrano 插件来进行更简单的部署工作。简单来说,Capistrano 是一个通过 SSH 并行的在多台机器上执行相同命令的工具,使用用来安装一整批机器。 它通过一个个已有的和用户自定制的任务让部署过程简单化。
清单 20. 安装 Capistrano
gem sources -a http://gems.github.com/ gem install Capistrano
然后在 config/deploy.rb 中配置要部署的服务器的地址,各种服务器的角色以及每个服务器统一的用户名和密码,如下面的样例配置:
清单 21. 配置 Capistrano
set :application, "test_app" # 应用的名称
set :scm_username, "test" # 资源库的用户名
set :scm_password, 'test' # 资源库的密码
set :repository, Proc.new {"--username #{scm_username}
--password #{scm_password} svn://localhost/test_app/trunk"}
# 资源库
set :user, "test" # 服务器 SSH 用户名
set :password, 'test' # 服务器 SSH 密码
set :deploy_to, "/var/www/#{application} "
# 在服务器上的部署路径,默认的部署路径是 /u/apps/#{application}
role :Web, 'Web.test_app.com' # 前端 Web 服务器
role :app, 'app1.test_app.com', 'app2.test_app.com', 'app3.test_app.com' #Rails 应用服务器
role :db, 'app1.test_app.com', :primary => true
# 运行 migrate 脚本的机器,通常为其中一台应用服务器。
在使用 Capistrano 进行部署的时候,通常是这样使用 cap sometask来运行任务。你可以先用 cap -h查看所有的选项,并用 cap -T查看现有的所有任务。如 cap migrate则在 role 为 db 的机器上执行 rake db:migrate命令。使用 Capistrano 的更多资料可以参考 http://wiki.capify.org 这个网站。另外,Capistrano 还可以使用在非 Rails 环境下进行自动部署,在配置好 ruby 环境和 Capistrano 插件后,再安装下面的插件即可:
清单 22. 非 Rails 环境使用 Capistrano
gem sources -a http://gems.github.com/ gem install leehambley-railsless-deploy
结束语
本文着重使用 Ruby On Rails 来开发和部署 Web 应用时一些有用的具体实践,没有具体去介绍一些通常应用程序都需要面对的普遍问题,如数据库的优化和分布式部署,这是一个大并发的 Web 应用都需要面对和解决的问题,比如可以采用 master-slave 的方式去部署分布式的数据库,或者采用分库或者分表的方式对数据库进行拆分。另外,在运行 Rails 服务器或者其它后台应用程序时,通过还需要另外的进程去进行监控,如用 God 去监控 Rails 进程也是一个 Rails 应用通常都会采用的策略。另外,很多时候,可以采用更敏捷更轻量级的 Rack 去代替 Rails 来进行更高效的开发的提供服务。并且,Engineyard ,Joyent 以及 Heroku 等这类 Rails 网络提供商的涌现也在相当程度上坚定了用 Rails 开发和部署大规模大并发 Web 应用的信心。虽然 Ruby On Rails 自身的缺陷不可避免, 但是开发可伸缩的高性能的应用程序并不是不可能的。本文希望能够帮助 Rails 开发人员快速掌握一些具体实践,能够编写出并部署性能高伸缩性强的 Web 应用程序。

